
Join our daily and weekly newsletters for the latest updates and the exclusive content on AI coverage. Learn more
Even if the language and reasoning models are popular, organizations are increasingly turning to smaller models to perform AI processes with less energy and cost concerns.
While some organizations distill larger models towards smaller versions, model suppliers like Google Continue to publish models of small languages (SLM) as an alternative to large language models (LLM), which can cost more to function without sacrificing performance or precision.
In this spirit, Google has published the latest version of its small model, Gemma, which offers extensive context windows, larger parameters and more multimodal reasoning capacities.
Gemma 3, which has the same power of treatment as larger Gemini 2.0 modelsRemains better used by smaller devices such as phones and laptops. The new model has four sizes: 1b, 4b, 12b and 27b settings.
With a larger 128K token window window – on the other hand, Gemma 2 Had a context window of 80K – Gemma 3 can include more information and complicated requests. Google has updated Gemma 3 to work in 140 languages, analyze the images, text and short videos and support functions to automate agent tasks and workflows.
Gemma gives solid performance
To further reduce computer costs, Google has introduced quantified gemma versions. Think about Quantified models as compressed models. This occurs by the process of “reducing the accuracy of digital values in the weights of a model” without sacrificing precision.
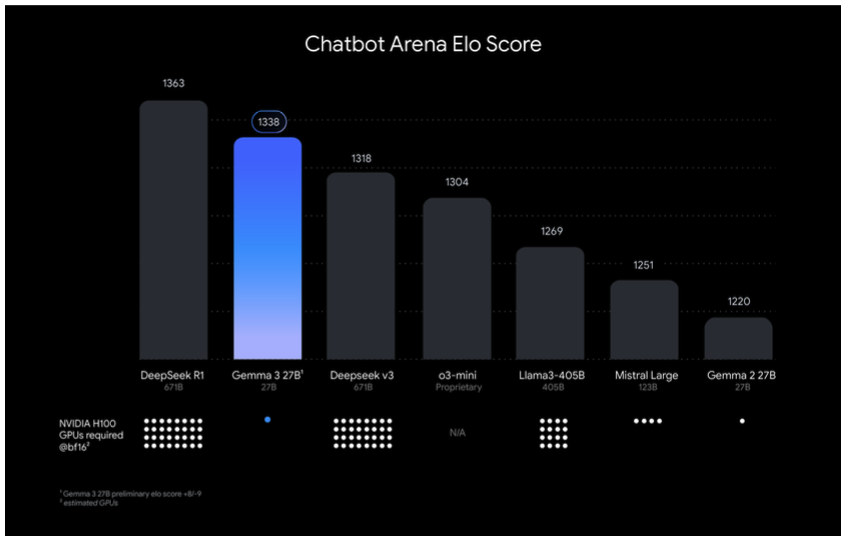
Google said Gemma 3 “offers advanced performance for its size” and surpasses the leading LLMS like Llama-405B, Deepseek-V3 and O3-Mini. Gemma 3 27b, in particular, arrived second in Deepseek-R1 in the score tests of Chatbot Arena Elo. He exceeded In depthSmaller model, Deepseek V3, OPENAI‘s o3-min, Meta‘s lelama-405b and Mistral Big.
By quantifying Gemma 3, users can improve performance, run the model and create applications “which can adapt to a single GPU and a tensor processing unit (TPU).”
Gemma 3 integrates with developer tools like Hugging Face Transformers, Olllama, Jax, Keras, Pytorch and others. Users can also access Gemma 3 via Google AI Studio, Hugging Face or Kaggle. Companies and developers can request access to the API Gemma 3 via AI Studio.
Gemma shield for safety
Google said that it has built security protocols in Gemma 3, including a security verifier for images called Shieldgemma 2.
“The development of Gemma 3 included in -depth governance of data, alignment with our security policies via fine and solid reference assessments,” writes Google in a blog article. “Although in -depth tests of more competent models often inform our less capable assessment, the improved performance of Gemma 3 have prompted specific assessments focused on its abusive potential for the creation of harmful substances; Their results indicate a low risk level. »»
SHIELDGEMMA 2 is a 4B parameter image safety verifier built on the Gemma 3 Foundation. He finds and prevents the model from responding with images containing sexually explicit content, violence and other dangerous materials. Users can personalize Shieldgemma 2 to meet their specific needs.
Small models and distillation increasing
Since the release of Google for the first time Gemma in February 2024SLMs have seen An increase in interest. Other small models like Microsoft Phi-4 And Mistral Small 3 Indicate that companies want to create applications with models as powerful as LLM, but not necessarily the extent of what an LLM is capable.
Companies have also started to turn to smaller versions of the LLM they prefer by distillation. To be clear, Gemma is not a distillation of Gemini 2.0; It is rather formed with the same data and architecture set. A distilled model learns from a larger model, which Gemma does not do.
Organizations often prefer to adapt to certain use cases to a model. Instead of deploying an LLM like O3-Mini or Claude 3.7 Sonnet to a simple code editor, a smaller model, whether it is a SLM or a distilled version, can easily perform these tasks without over-adjustment of a huge model.







